Introduction to Machine Learning
Table of Contents
Tasks
Tabular Data
- Regression Tasks
- Classification Tasks
- Time Series Forecasting
Regression Tasks
Predicting continuous outcomes, such as sales forecasting or real estate pricing.
Classification Tasks
Categorizing data into predefined groups, like customer churn prediction or disease diagnosis.
Time Series Forecasting
Predicting future values based on historical time series data, like stock market trends or demand forecasting.
Computer Vision
- Image Classification
- Object Detection
- Image Segmentation
- Video Analysis
Image Classification
What is image classification? Basics you need to know
Object Detection
Exploring Object Detection Applications and Benefits
Image Segmentation
Object Segmentation
Video Analysis
Football's video analysis revolution: From the top clubs to the masses
Natural Language Processing (NLP)
- Sentiment Analysis
- Text Classification
- Machine Translation
- Named Entity Recognition (NER)
Sentiment Analysis
Sentiment Analysis: A Definitive Guide
Text Classification
Text Classification
Machine Translation
🇺🇸: I'm a cat.
↓
🇨🇳: 我是一只猫。
🇩🇪: ich bin eine Katze
🇯🇵: 吾輩は猫である。
Named Entity Recognition (NER)
Named Entity Recognition and Classification with Scikit-Learn
Reinforcement Learning
- Game AI
- Simulation Optimization
Game AI
Getting Started With Reinforcement Learning
Simulation Optimization
Getting Started With OpenAI Gym: The Basic Building Blocks
Anomaly Detection
- Fraud Detection
- Network Intrusion Detection
Fraud Detection
Identifying fraudulent activities in financial transactions.
Network Intrusion Detection
Detecting malicious activities in network traffic.
Machine Learning Algorithms
- Liner Regression
- Logistic Regression
- Decision Tree
- SVM (Support Vector Machine)
- Naive Bayes Algorithm
- KNN (K-Nearest Neighbors) Algorithm
- K-Means
- Random Forest Algorithm
- Gradient Boosting
Linear Regression
Animated Machine Learning Classifiers
Logistic Regression
Building an End-to-End Logistic Regression Model
Decision Tree
Animated Machine Learning Classifiers
SVM (Support Vector Machine)
Animated Machine Learning Classifiers
Naive Bayes Algorithm
\[\begin{aligned} P(A|B) &= \frac{P(B|A)P(A)}{P(B)} \end{aligned}\]KNN (K-Nearest Neighbors) Algorithm
Animated Machine Learning Classifiers
K-Means
File:K-means convergence.gif
{kind=link}
Random Forest Algorithm
Animated Machine Learning Classifiers
Gradient Boosting
Animated Machine Learning Classifiers
Exploratory Data Analysis (EDA)
Get domain knowledge.
If you know that many people take taxi to the airport, you can add the distance to the airport as a feature.
Descriptive Statistics
df.describe()
# count mean std min 25% 50% 75% max
# var1 1000.0 12.542000 6.735307 0.0 8.00 12.0 18.0 24.0
# var2 1000.0 0.255000 0.435941 0.0 0.00 0.0 1.0 1.0
Find missing data.
df.isnull().sum()
# var1 12
# var2 3
# dtype: int64
Correlation Matrix
df.corr()
# var1 var2
# var1 1.000000 -0.121675
# var2 -0.121675 1.000000
Value Counts for Categorical Data
df['Column3'].value_counts()
# True 500
# False 490
# NaN 10
Unique Values in a Column
df['Column2'].unique()
# array([5, 6, 7, ..., 53, 54, 55])
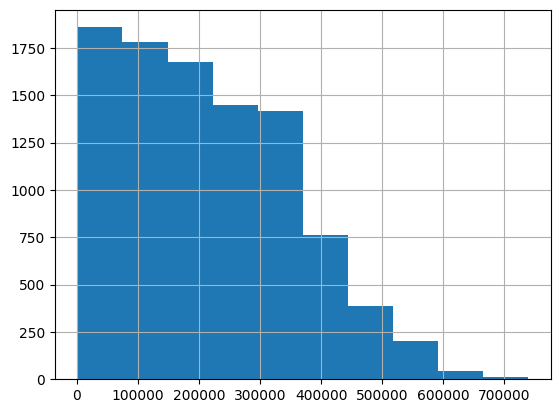
Histograms
df['Column2'].hist()
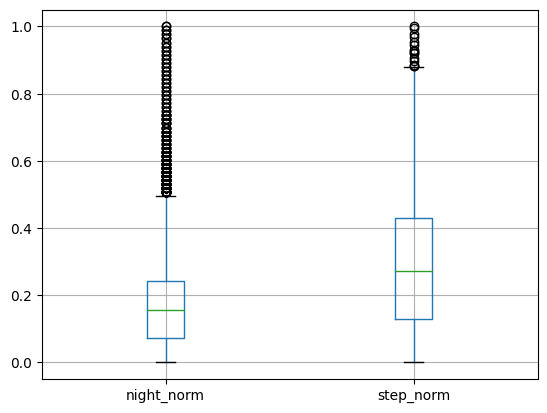
Box Plots
df.boxplot(column=["Column1", "Column2"])
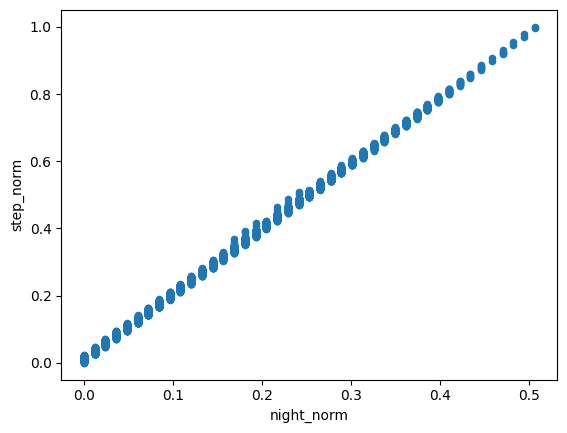
Scatter Plot
df.plot.scatter(x='Column1', y='Column2')
Heatmap for Correlation
sns.heatmap(df.corr(), annot=True)

Data Preprocessing
Handling Missing Values
# Fill missing values
df.fillna(value)
# Drop rows/columns with missing values
df.dropna(axis=0, how='any')
Data Type Conversion
df['column'].astype('dtype')
Outlier Removal
df[df['column'] < upper_limit]
Normalization and Scaling
from sklearn.preprocessing import MinMaxScaler, StandardScaler
scaler = MinMaxScaler() # or StandardScaler()
df_scaled = scaler.fit_transform(df)
Encoding Categorical Data
# Using get_dummies
pd.get_dummies(df, columns=['categorical_column'])
# Using category codes
df['categorical_column'] = df['categorical_column'].astype('category').cat.codes
Feature Engineering
df['new_feature'] = df['column1'] / df['column2']
Handling Date and Time
df['year'] = df['datetime_column'].dt.year
Dimensionality Reduction
from sklearn.decomposition import PCA
pca = PCA(n_components=k)
df_reduced = pca.fit_transform(df)
Validation
Hold-Out Validation
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(df.drop('target', axis=1), df['target'], test_size=0.2)
K-Fold Cross-Validation
from sklearn.model_selection import cross_val_score, KFold
kf = KFold(n_splits=5)
scores = cross_val_score(model, X, y, cv=kf)
Stratified K-Fold Cross-Validation
from sklearn.model_selection import StratifiedKFold
skf = StratifiedKFold(n_splits=5)
scores = cross_val_score(model, X, y, cv=skf)
Metrics Optimization
Accuracy
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_true, y_pred)
Precision, Recall, and F1 Score
from sklearn.metrics import precision_score, recall_score, f1_score
precision = precision_score(y_true, y_pred)
recall = recall_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)
ROC-AUC Score
from sklearn.metrics import roc_auc_score
roc_auc = roc_auc_score(y_true, y_scores)
MSE and RMSE
from sklearn.metrics import mean_squared_error
mse = mean_squared_error(y_true, y_pred)
rmse = mean_squared_error(y_true, y_pred, squared=False)
Mean Absolute Error (MAE)
from sklearn.metrics import mean_absolute_error
mae = mean_absolute_error(y_true, y_pred)
Log Loss
from sklearn.metrics import log_loss
logloss = log_loss(y_true, y_pred_probs)
Ensembling
Averaging
predictions = (model1.predict(X_test) + model2.predict(X_test) + model3.predict(X_test)) / 3
Weighted Averaging
weights = [0.3, 0.4, 0.3]
predictions = weights[0]*model1.predict(X_test) + weights[1]*model2.predict(X_test) + weights[2]*model3.predict(X_test)
Bagging
from sklearn.ensemble import BaggingClassifier
bagging_model = BaggingClassifier(base_estimator=DecisionTreeClassifier(), n_estimators=100)
bagging_model.fit(X_train, y_train)
predictions = bagging_model.predict(X_test)
Boosting
from sklearn.ensemble import GradientBoostingClassifier
boosting_model = GradientBoostingClassifier(n_estimators=100)
boosting_model.fit(X_train, y_train)
predictions = boosting_model.predict(X_test)
Stacking
from sklearn.ensemble import StackingClassifier
from sklearn.linear_model import LogisticRegression
estimators = [
('rf', RandomForestClassifier(n_estimators=10, random_state=42)),
('svr', make_pipeline(StandardScaler(), LinearSVC(random_state=42)))
]
stacking_model = StackingClassifier(estimators=estimators, final_estimator=LogisticRegression())
stacking_model.fit(X_train, y_train)
predictions = stacking_model.predict(X_test)